

Anthropic publicó nuevos detalles sobre los controles de ciberseguridad asociados a Claude Fable 5, modelo que volvió a estar disponible globalmente. El eje de la actualización está en separar usos dañinos, usos de doble propósito y tareas defensivas que pueden ser necesarias para equipos de seguridad.

¿Qué resguardos aplica Fable 5 en tareas cibernéticas?
La compañía explicó que el desafío está en el carácter dual de muchas capacidades de ciberseguridad. Un modelo puede ayudar a revisar código para encontrar vulnerabilidades, pero esa misma capacidad puede ser usada como paso previo a un ataque si no existen controles adecuados.
Para ordenar ese riesgo, Anthropic describe cuatro categorías de uso para sus clasificadores de seguridad. Los usos prohibidos se bloquean, los usos de doble propósito de alto riesgo también se bloquean, las actividades de bajo riesgo pueden ser monitoreadas o bloqueadas en algunos casos, y las acciones benignas deberían permitirse con cierto seguimiento.
El listado de usos prohibidos incluye ransomware, sabotaje de procesos físicos, evasión de defensas, canales de comando y control, exfiltración de datos, desarrollo o mejora de malware, entrega de software malicioso y ataques contra infraestructura central de Internet. En la práctica, Anthropic asume que algunos de estos elementos pueden tener valor defensivo, pero privilegia el bloqueo por su potencial de daño.
El margen de seguridad aumenta los falsos positivos
La empresa también detalló el uso de un margen de seguridad más amplio para Fable 5 que en modelos anteriores. Ese margen puede bloquear peticiones benignas o de bajo riesgo cuando no parecen suficientemente seguras para los clasificadores.
La decisión expone una tensión operativa relevante para organizaciones que integran IA en procesos de seguridad. Un filtro más estricto reduce la probabilidad de habilitar conductas peligrosas, pero también puede limitar tareas legítimas como análisis de logs, administración de red, gestión de parches o respuesta ante incidentes.
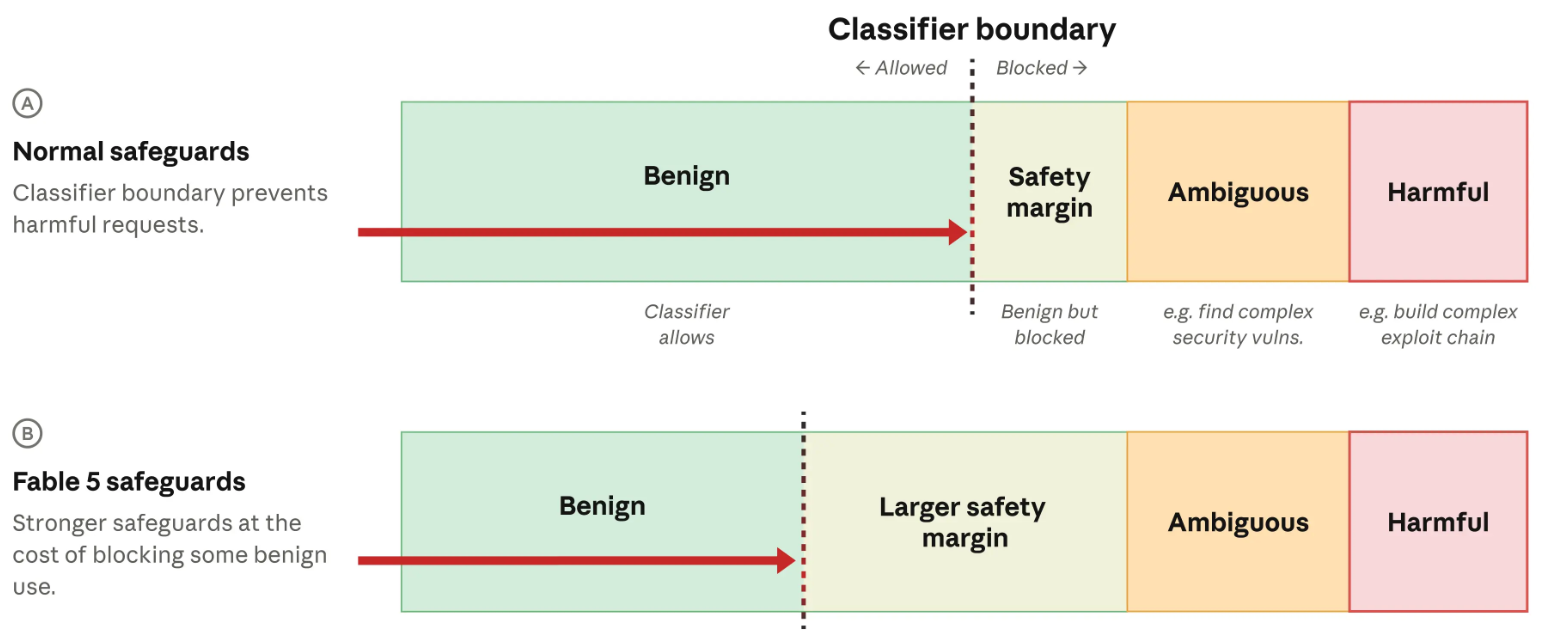
La imagen permite entender la decisión técnica como un cambio de umbral, no como un bloqueo absoluto de toda tarea de ciberseguridad. En Fable 5, el límite se desplaza hacia una zona más conservadora, donde algunas solicitudes benignas pueden quedar retenidas por precaución.
Una escala para medir la gravedad de los jailbreaks
Anthropic propuso además un borrador de marco para evaluar la severidad de jailbreaks de IA en tareas cibernéticas. La escala Cyber Jailbreak Severity, o CJS, va desde CJS-0 informativo hasta CJS-4 crítico, con niveles pensados como bandas de gravedad crecientes.
El puntaje se calcula a partir de cuatro ejes. La ganancia de capacidad mide cuánto aporta el jailbreak por sobre herramientas ya disponibles, la amplitud evalúa si funciona en varias tareas ofensivas, la facilidad de uso estima cuánto esfuerzo requiere convertirlo en ataque, y la descubribilidad mide qué tan accesible está la técnica para actores de amenaza.
Según la propuesta, un caso crítico sería una técnica pública y reutilizable capaz de desactivar controles de seguridad en distintas categorías ofensivas. En el extremo bajo, un hallazgo sin ganancia real frente a herramientas públicas se considera informativo y no escala en la clasificación.

El debate apunta a un lenguaje común sobre riesgo
Anthropic plantea el marco como una versión inicial destinada a recibir comentarios de academia, industria, sociedad civil y gobiernos. También habilitó un programa en HackerOne para que investigadores reporten posibles jailbreaks cibernéticos en Fable 5.
Para la alta gerencia, el punto relevante es que la seguridad de modelos avanzados ya no se mide solo por si responden o bloquean una consulta. La discusión pasa por establecer categorías de riesgo comparables, criterios de severidad y mecanismos de reporte que permitan distinguir entre investigación defensiva, uso de doble propósito y capacidades que podrían aumentar el riesgo operacional.











{kind=link}