

Por Alper Ilkbahar, director de Tecnología en Sandisk
La inteligencia artificial (IA) avanza de manera imparable en todo el ámbito de la computación. Aunque actualmente casi uno de cada siete centros de datos está equipado para alojar cargas de trabajo de IA, se espera que esta cifra se acerque al 70% en el 2030.

La IA está migrando de los entornos de hiperescala a los centros de datos empresariales y al perímetro de la red, donde se proyecta que las aplicaciones de IA en el borde generen casi USD $66,500 millones hacia finales de la década. El combustible de esta nueva era de la computación son los datos: volúmenes gigantescos que deben ingresarse a alta velocidad en una infraestructura de computación de IA demandante y rápidamente escalable.
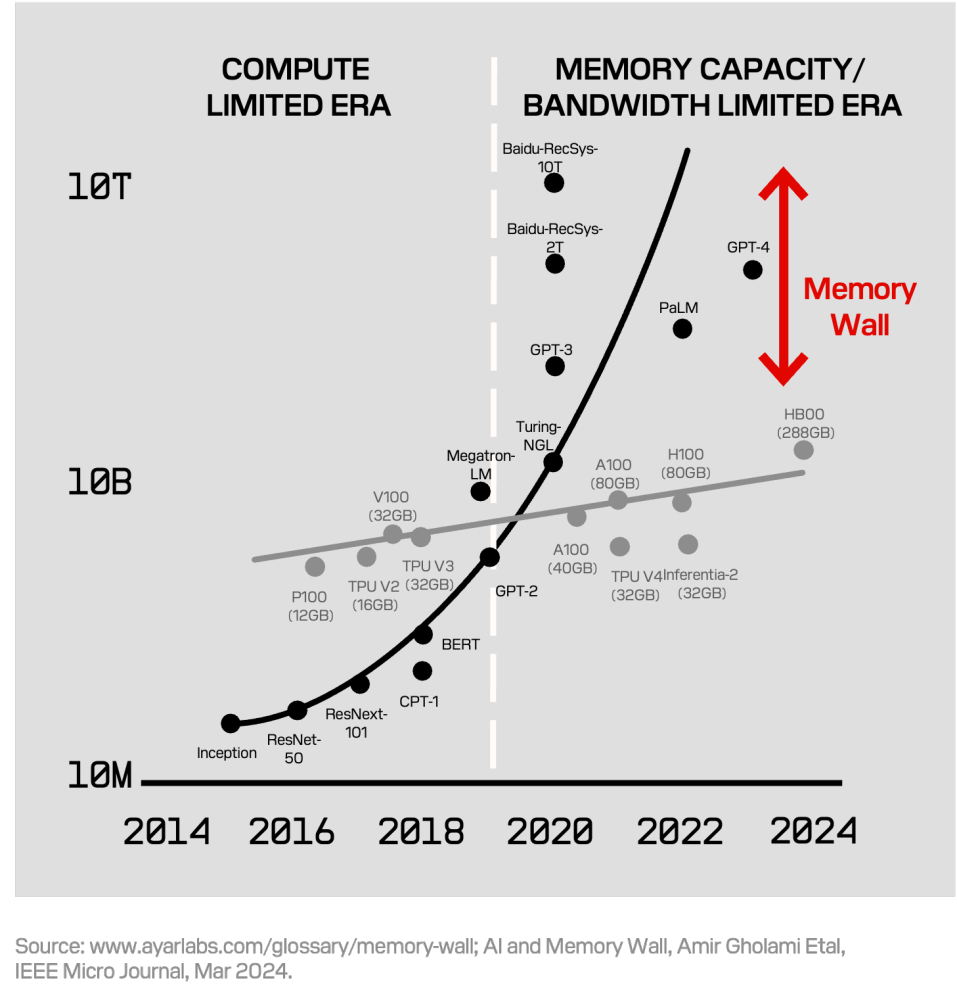
Estos enormes repositorios de contenido están saturando las estructuras de almacenamiento convencionales y ponen en evidencia una debilidad arquitectónica inherente. La memoria para centros de datos (DRAM y la memoria especializada de ancho de banda alto conocida como HBM) tienen cada vez más dificultades para seguir el ritmo de las crecientes demandas de los grandes modelos de IA en términos de densidad, capacidad de almacenamiento y escalabilidad.

Por otra parte, los fabricantes de sistemas de cómputo hiperescalado enfrentan costos de producción de DRAM y HBM cada vez más altos, así como una mayor complejidad de diseño y consumo energético. El desafío es aún mayor en los centros de datos empresariales y las aplicaciones de IA en el borde, donde un espacio físico proporcionalmente más reducido afecta su capacidad de absorber el incremento de costos de memoria y consumo energético.
Existe además otro problema urgente relacionado con la inferencia de IA, que ahora es la carga de trabajo dominante y tiene requisitos de gestión de datos distintos al entrenamiento de IA. La inferencia almacena modelos de IA grandes, y en crecimiento, y la memoria basada en HBM y DRAM ha demostrado carecer de la capacidad y escalabilidad de costos necesarias para satisfacer estas nuevas demandas. En vista de estas características de memoria claramente diferentes, surge la oportunidad de desarrollar una tecnología de memoria optimizada específicamente para la inferencia de IA.

¿Por qué DRAM y HBM no logran abastecer las cargas de trabajo de inferencia de IA?
Para entender por qué la DRAM y la HBM por sí solas son subóptimas para la implementación de IA a largo plazo, consideremos las siguientes desventajas. Estas comienzan como pequeñas grietas, pero si no se corrigen, se expandirán con el tiempo y debilitarán los cimientos del almacenamiento de próxima generación centrado en IA.
Limitaciones de densidad: La escalabilidad de capacidad de la DRAM se ha estancado, mientras que la necesidad de mayor capacidad para la inferencia de IA sigue aumentando
Desajuste con la inferencia de IA: La ventaja de la baja latencia y las características de acceso aleatorio de la memoria DRAM no son relevantes para la inferencia de IA, donde los patrones de acceso son deterministas y más tolerantes a la latencia gracias a técnicas como la precarga de datos.

Atributos de una arquitectura de memoria optimizada para la inferencia de IA
Estas limitaciones se extienden por debajo de una industria de DRAM de USD $120,000 millones que busca mantener su posición en los centros de datos, considerando que el gasto de los proveedores de hiperescala en infraestructura de IA podría alcanzar los USD $6.7 trillones hacia finales de la década5.
¿Qué pasaría si fuera momento de empezar de nuevo y diseñar una nueva memoria desde cero adaptada a las necesidades de la aplicación, en lugar de forzar la aplicación a adaptarse a la memoria?

Una memoria de almacenamiento optimizada para IA debería contar con los siguientes atributos:
- Mayor capacidad de memoria escalable para cargas de inferencia
- Mayor densidad de memoria (GB/mm²)
- Ancho de banda alto para cumplir los requisitos de la inferencia de IA
- Menor consumo energético a nivel de sistema
- Métricas de bajo costo ($/TB)
High Bandwidth Flash apunta al centro de datos de IA
High Bandwidth Flash (HBF) es una nueva e innovadora arquitectura de memoria diseñada específicamente para impulsar la próxima generación de computación de IA. HBF cumple con los requisitos de capacidad, energía, rendimiento y escalabilidad de las aplicaciones avanzadas y de uso intensivo de datos.
En comparación con la HBM, la HBF ofrece mayor capacidad y densidad de memoria con un ancho de banda comparable que se alinea mejor con las tendencias de la inferencia de IA. Como medio de almacenamiento persistente, la HBF también conserva los datos cuando se pierde la energía y es térmicamente estable, lo que le permite operar a altas temperaturas.

Para lograr estas ventajas, la HBF aprovecha el diseño y la tecnología de fabricación BiCS de Sandisk, así como su arquitectura de chips, que rediseña de manera eficaz la memoria NAND flash para optimizar el ancho de banda alto y las características de la inferencia. El uso de tecnología de obleas CMOS Bonded Array (CBA) mejora aún más la eficiencia energética y el ancho de banda.
La HBF reinventa la memoria flash NAND para las aplicaciones de IA
En comparación con la memoria NAND convencional, el uso de paralelismo, escalamiento lógico avanzado y técnicas de apilamiento personalizadas en HBF ayuda a ofrecer una menor latencia y un ancho de banda de lectura significativamente mayor, lo que permite a los modelos de lenguaje de gran tamaño transmitir datos a velocidades similares a DRAM
La HBF también soporta grandes cachés KV para manejar de manera eficiente comandos largos y complejos, así como datos específicos de clientes o dominios que mejoran la precisión de la inferencia de IA.
Expandiendo la IA centrada en memoria hacia la empresa y en el borde de la red
Dado que HBM no suele estar disponible para entornos móviles y en el borde debido a sus limitaciones de densidad, costo y consumo energético, el valor de contar con una mayor capacidad de memoria para gestionar problemas de inferencia de IA más complejos se materializa con HBF.
Esto abre la puerta a los dispositivos en el borde, como los teléfonos inteligentes, que son capaces de tomar decisiones en tiempo real para realizar una variedad de tareas sofisticadas. Gracias a su memoria persistente, HBF tiene la capacidad de recuperar el contexto antiguo de consultas previas para resolver problemas nuevos.

Las ventajas de la HBF se extienden a la computación empresarial, donde la base de usuarios es mucho menor que en los centros de hiperescala y los grandes clústeres de GPU soportados por HBM resultan demasiado costosos. Con la adopción de aceleradores habilitados con HBF, las empresas más pequeñas pueden potencialmente ajustar modelos grandes previamente entrenados para usos específicos de su dominio.
La memoria optimizada elimina los obstáculos para el crecimiento de la IA
A nuestro alrededor, los centros de datos y dispositivos de IA en el borde operan de manera autónoma, realizando tareas que abarcan desde recetas para la cena hasta descubrimientos científicos innovadores.
Las tareas rutinarias, como el alojamiento de sitios web y la gestión de datos empresariales, están dando paso a cargas de trabajo inteligentes que generan información útil a través del aprendizaje automático, el aprendizaje profundo y el análisis de datos.
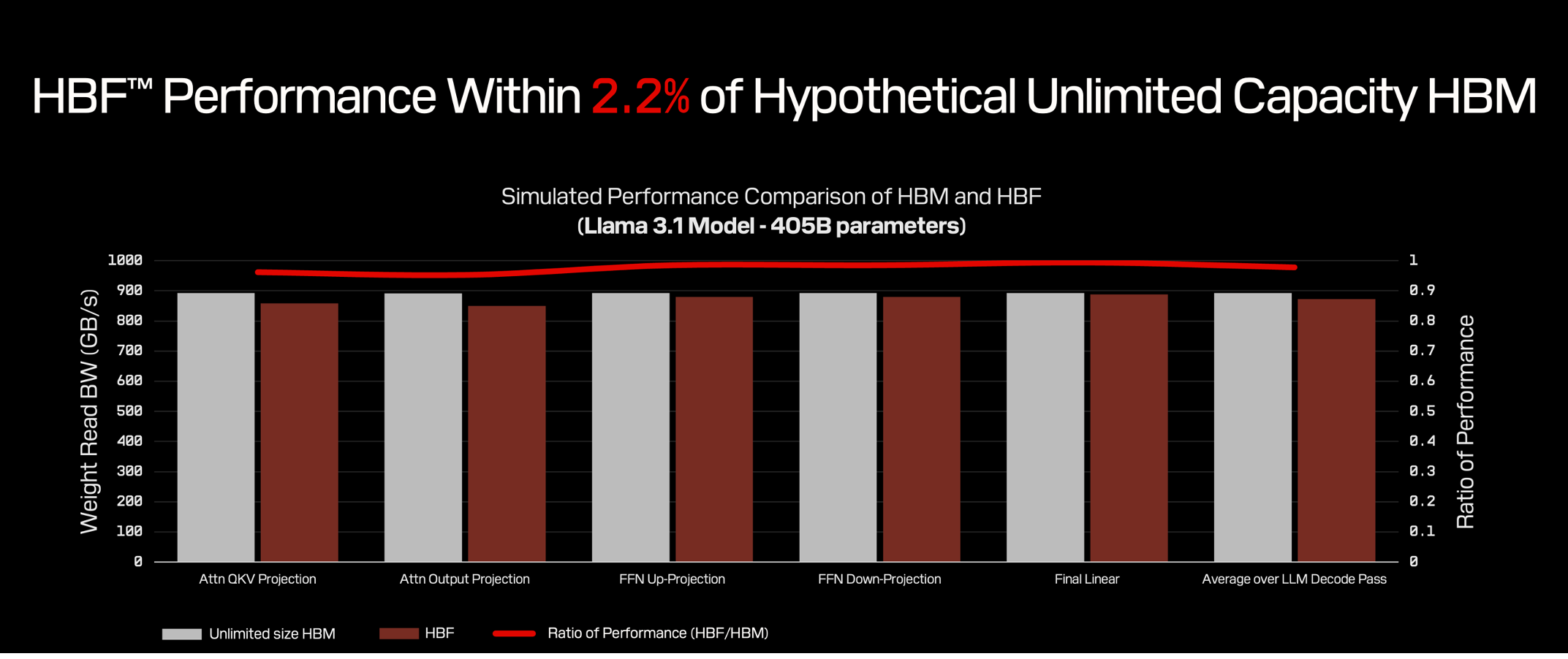
Es momento de reconsiderar cómo se aprovisiona la memoria en los centros de datos y en el borde para gestionar modelos de inferencia a gran escala capaces de realizar predicciones y generar resultados. En comparación con la HBM, la HBF ofrece una clara ventaja en capacidad, al tiempo que mantiene el alto rendimiento requerido por las aplicaciones de inferencia de IA.
Como nueva tecnología de memoria escalable, la HBF ayuda a reducir los cuellos de botella y acelera la obtención de información para las aplicaciones de IA tanto en los centros de datos modernos como en las redes en el borde.
















{kind=link}