

NVIDIA incorporó optimizaciones para la familia Gemma 4 de Google con el objetivo de habilitar ejecución local en GPU RTX, DGX Spark y módulos Jetson Orin Nano. El alcance del movimiento se concentra en llevar modelos abiertos a entornos donde importan latencia baja, operación offline y acceso a contexto local en tiempo real.

Gemma 4 queda posicionada para despliegues que van desde el borde hasta plataformas de mayor capacidad
La familia considerada incluye variantes E2B, E4B, 26B y 31B. NVIDIA la sitúa como una base escalable para ejecutar IA en formatos que cubren desde dispositivos de borde hasta sistemas con mayor capacidad de cómputo.
Los modelos E2B y E4B quedan orientados a inferencia ultraficiente y de baja latencia en el borde. En paralelo, las versiones 26B y 31B apuntan a razonamiento de mayor nivel y a cargas centradas en desarrollo sobre RTX y DGX Spark.
En términos funcionales, Gemma 4 cubre razonamiento, generación y depuración de código, uso estructurado de herramientas mediante function calling y capacidades multimodales para visión, video y audio. A ello se suma soporte para entradas multimodales intercaladas y compatibilidad nativa con más de 35 idiomas, con preentrenamiento sobre más de 140 idiomas.

NVIDIA orienta Gemma 4 a asistentes locales, automatización y flujos de desarrollo
La integración se enfoca en escenarios de IA orientada a agentes que operan de manera local. Dentro de ese marco, la compatibilidad con OpenClaw permite construir agentes capaces de tomar contexto desde archivos, aplicaciones y flujos de trabajo.
En ese plano técnico, NVIDIA también incorpora una referencia de desempeño para Gemma 4 sobre llama.cpp en hardware cliente de alta gama.
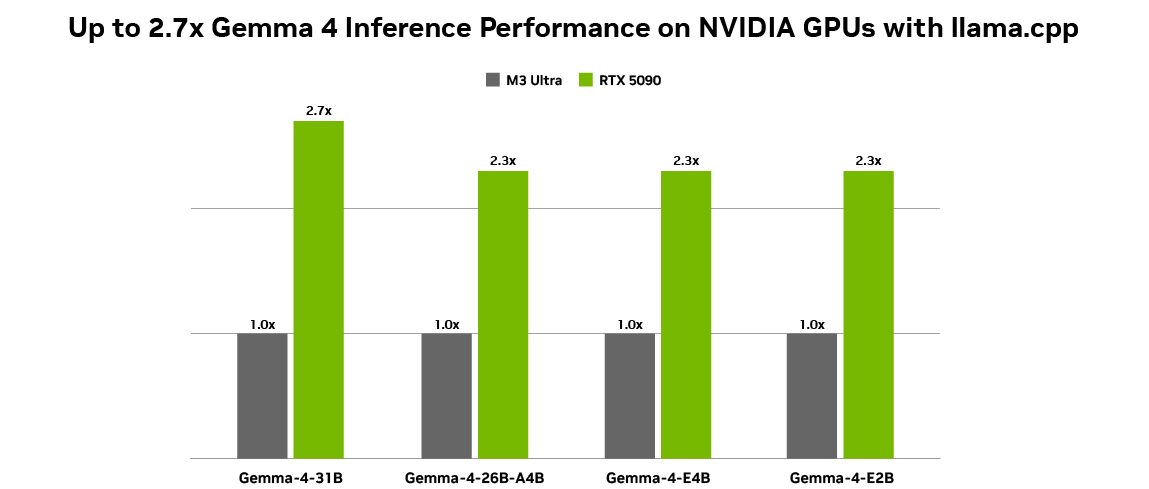
Para el despliegue, NVIDIA indica soporte con Ollama y llama.cpp, además de respaldo inicial de Unsloth con modelos optimizados y cuantizados para ajuste fino e implementación local mediante Unsloth Studio. Con ello, Gemma 4 entra a una ruta de adopción que cubre tanto experimentación como puesta en marcha en infraestructura cercana al usuario.
La base técnica que sostiene esta ejecución combina Tensor Cores para acelerar inferencia y la pila CUDA para mantener compatibilidad amplia con frameworks y herramientas. Ese conjunto permite que Gemma 4 se ejecute desde Jetson Orin Nano hasta PCs RTX, estaciones de trabajo y DGX Spark sin exigir una adaptación extensa por plataforma.









{kind=link}