

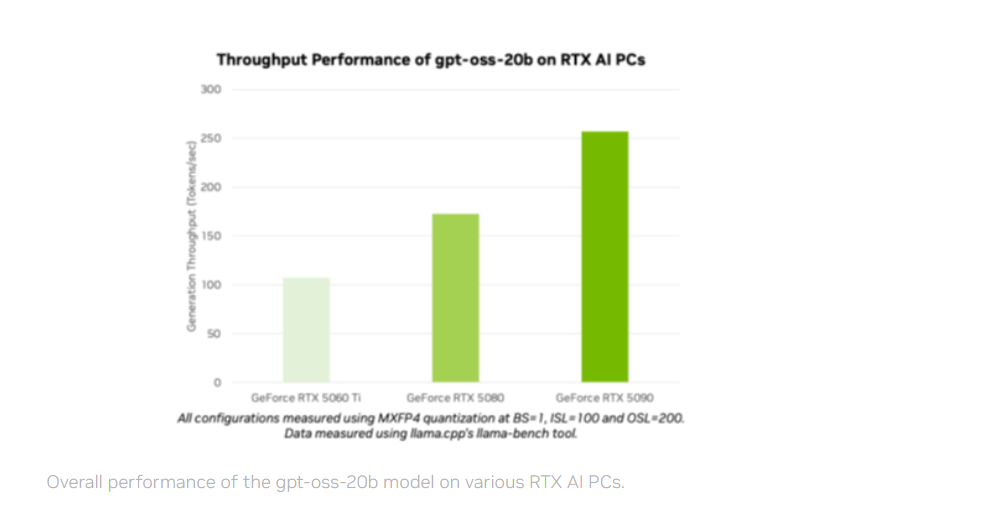
OpenAI presentó los modelos de código abierto gpt-oss-20b y gpt-oss-120b optimizados para GPUs NVIDIA RTX, permitiendo inferencia rápida desde la nube hasta el PC. Ofrecen razonamiento avanzado y un rendimiento de hasta 256 tokens por segundo en una GeForce RTX 5090.
¿Cómo transforman los modelos gpt-oss el desarrollo de IA local?
Los gpt-oss, con arquitectura mixture-of-experts, ajustan el nivel de razonamiento y admiten herramientas, lo que los hace versátiles para múltiples tareas. Soportan contextos de hasta 131.072 tokens, ideales para búsquedas, programación o análisis documental.

Entrenados en GPUs NVIDIA H100, son los primeros con soporte MXFP4 en RTX, ofreciendo alta calidad y menor consumo de recursos. Esto facilita su implementación en entornos que demandan velocidad y eficiencia en IA.
Ollama permite probarlos en GPUs con al menos 24GB de VRAM y añade funciones como soporte para PDF, texto e imágenes en chats. Puede usarse por línea de comandos o mediante SDK para integrarlo en flujos de trabajo.

También están disponibles en llama.cpp y Microsoft AI Foundry Local, que usa ONNX Runtime optimizado con CUDA y tendrá soporte para NVIDIA TensorRT, junto con mejoras en bibliotecas como GGML para maximizar rendimiento, así lo detalla: Jensen Huang, fundador y CEO de NVIDIA:
“OpenAI mostró al mundo lo que podía construirse sobre NVIDIA AI — y ahora están impulsando la innovación en software de código abierto”.
Esta visión refuerza el papel de la colaboración tecnológica para acelerar el desarrollo de la inteligencia artificial, creando un ecosistema abierto que favorece tanto la innovación como la competitividad global, afirmó el ejecutivo:
“Los modelos gpt-oss permiten a desarrolladores de todo el mundo construir sobre esa base de vanguardia, fortaleciendo el liderazgo tecnológico de EE. UU. en IA, todo sobre la infraestructura de cómputo de IA más grande del mundo”.














{kind=link}