

DeepSeek liberó V4 Preview, una nueva familia de modelos de pesos abiertos orientada a razonamiento, programación, agentes y tareas de contexto extendido. La serie incluye DeepSeek-V4-Pro, con 1,6 billones de parámetros totales y 49.000 millones activos, además de DeepSeek-V4-Flash, con 284.000 millones de parámetros y 13.000 millones activos.
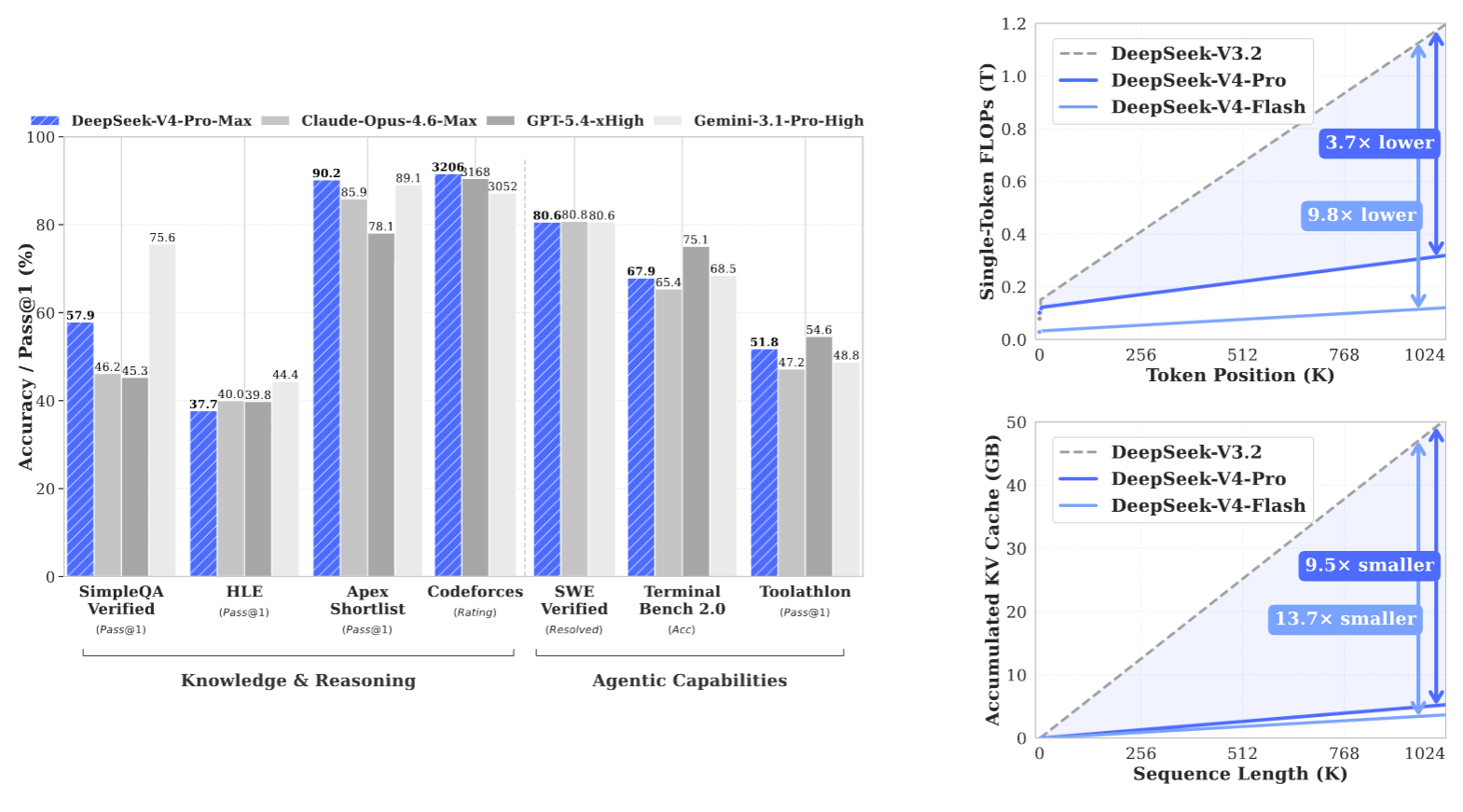
El anuncio instala una presión competitiva directa sobre los modelos cerrados de mayor costo, no solo por rendimiento declarado, sino por el intento de llevar ventanas de 1 millón de tokens a servicios oficiales y API.

Arquitectura MoE y eficiencia para contexto de 1 millón de tokens
La base técnica de DeepSeek-V4 mantiene una arquitectura Mixture-of-Experts, donde solo una parte del modelo se activa durante la inferencia. Este enfoque permite separar escala total y costo operativo, con una versión Pro orientada a máximo rendimiento y una versión Flash enfocada en menor latencia y eficiencia económica.
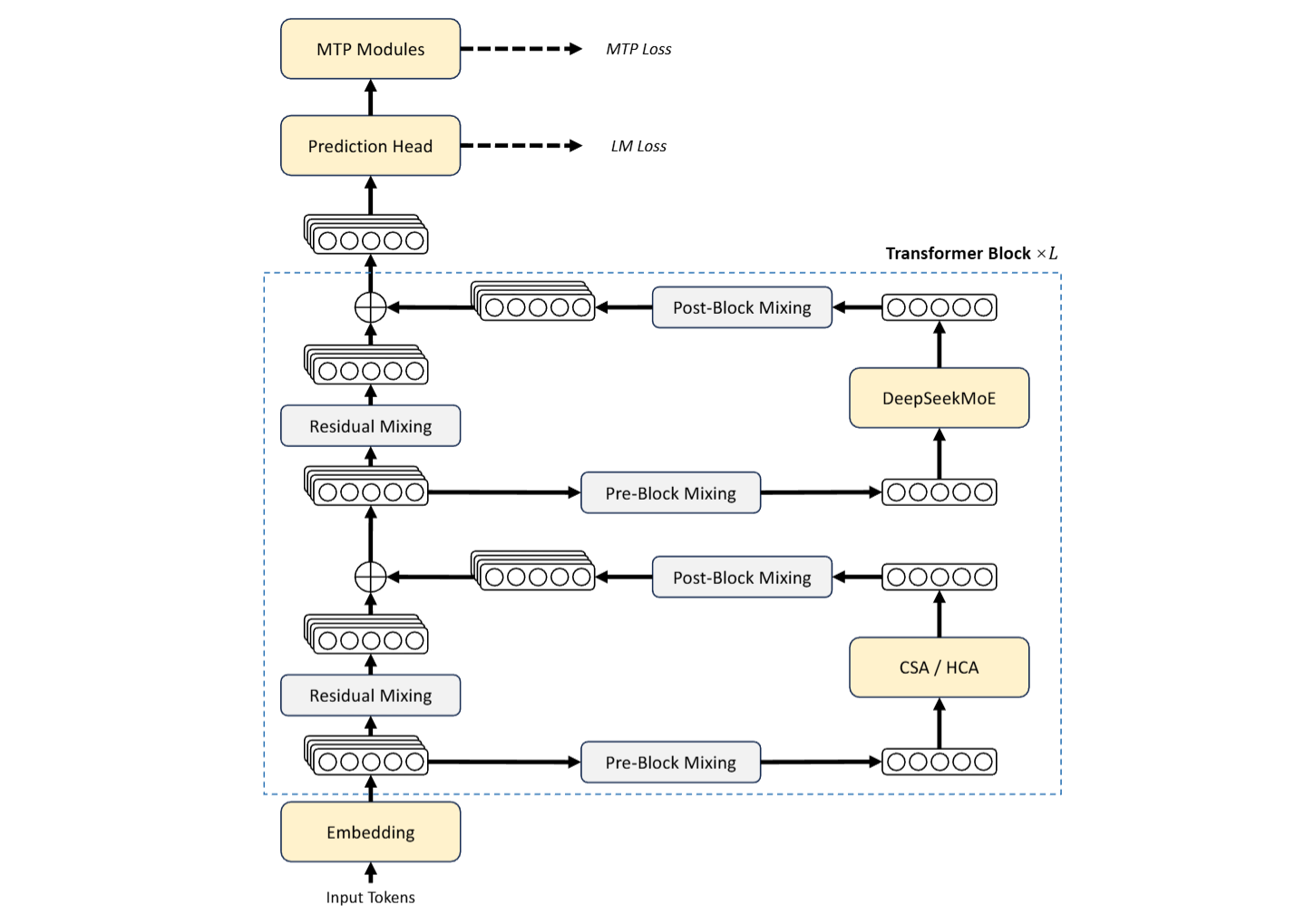
El reporte técnico atribuye el salto de contexto a una combinación de Compressed Sparse Attention, Heavily Compressed Attention, Manifold-Constrained Hyper-Connections y el optimizador Muon. En términos prácticos, estas piezas buscan reducir el costo de procesar secuencias muy largas sin abandonar tareas de razonamiento, código o flujos agénticos.
En el escenario de 1 millón de tokens, DeepSeek reporta que V4-Pro requiere 27% de los FLOPs de inferencia por token y 10% de la caché KV frente a DeepSeek-V3.2. V4-Flash reduce aún más esos valores, con 10% de los FLOPs y 7% de la caché KV respecto del mismo punto de comparación.

API, precios y lectura competitiva frente a modelos cerrados
DeepSeek indicó que V4-Pro y V4-Flash ya están disponibles en API, con soporte para formatos compatibles con OpenAI Chat Completions y Anthropic API. Ambos modelos admiten modo Thinking y Non-Thinking, mientras que los nombres deepseek-chat y deepseek-reasoner quedarán fuera de operación después del 24 de julio de 2026.
El esquema de precios refuerza el posicionamiento de eficiencia. DeepSeek-V4-Flash cuesta USD 0,14 por millón de tokens de entrada con cache miss y USD 0,28 por millón de tokens de salida, mientras que V4-Pro figura con tarifa promocional de USD 0,435 y USD 0,87 hasta el 5 de mayo de 2026, frente a precios base de USD 1,74 y USD 3,48.
La comparación pública apunta a una disputa más amplia por costo, rendimiento y control de infraestructura. Xataka destaca que DeepSeek no reveló el hardware usado para entrenar el modelo, pero consigna que V4 fue desarrollado para operar tanto sobre chips NVIDIA como sobre Huawei Ascend, un dato relevante para empresas que evalúan dependencia tecnológica y continuidad de suministro.
Para alta gerencia, el valor del anuncio está menos en un benchmark aislado y más en la combinación de tres factores: contexto extendido, pesos abiertos y estructura de costos. Si el rendimiento real confirma las cifras reportadas, DeepSeek-V4 podría aumentar la presión sobre proveedores cerrados en cargas de programación, análisis documental masivo y automatización con agentes.














{kind=link}