

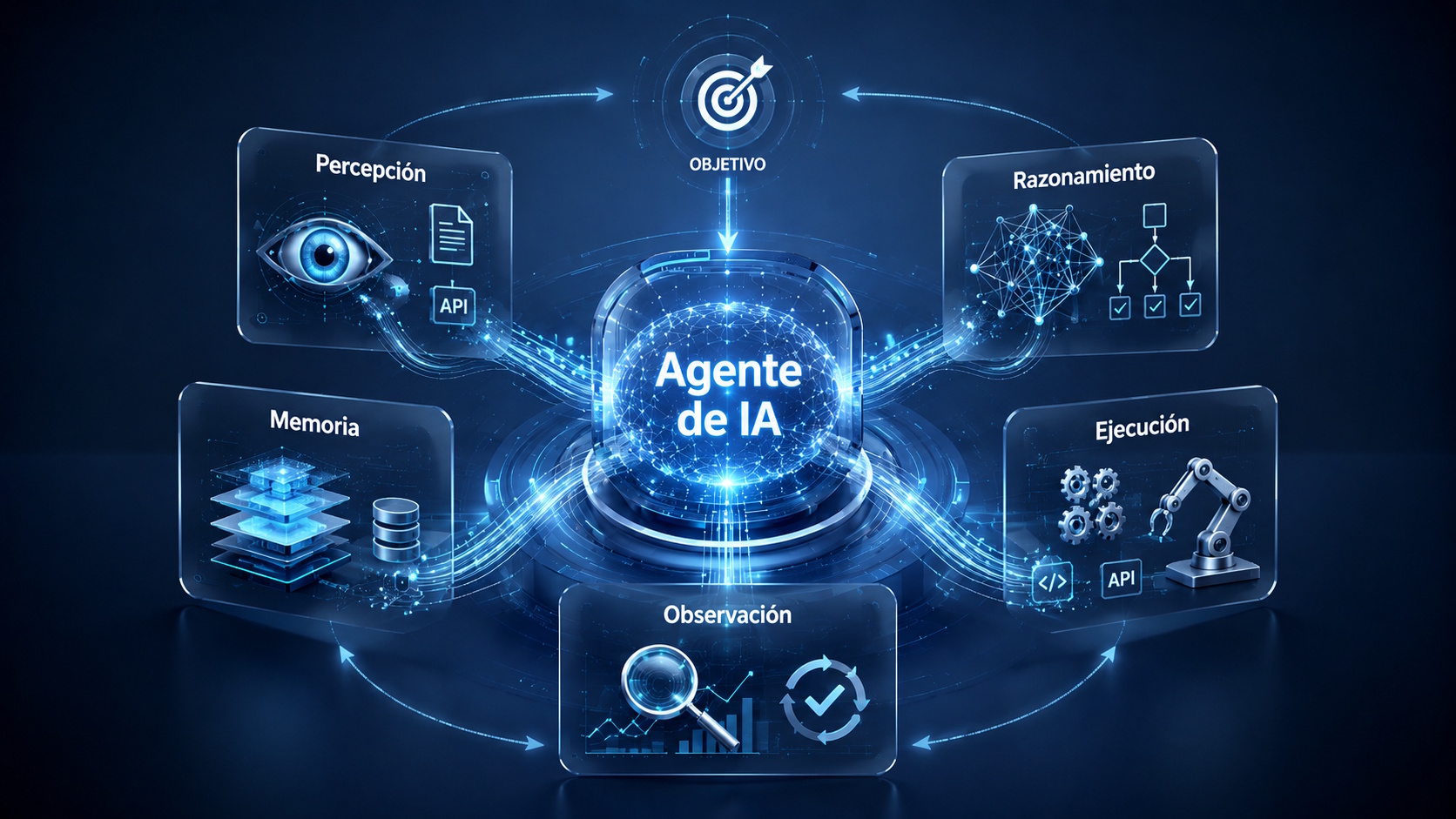
La adopción empresarial de agentes de IA está llevando la discusión más allá del modelo de lenguaje. Cuando estos sistemas pasan de una prueba a flujos con datos internos, APIs y servicios reales, la arquitectura empieza a pesar tanto como la capacidad de respuesta del LLM.
Polkan García es Oracle Cloud Pilot y Senior Director AI & Cloud para América Latina en Oracle, con más de 20 años de experiencia en servicios tecnológicos, gestión y liderazgo de equipos. Su análisis ubica a Oracle Database como una capa operativa previa al modelo, donde importan la ubicación del dato, el componente que controla la ejecución y la capacidad de mantener contexto cuando un agente trabaja con información empresarial.

El dato como plano de control
En una arquitectura corporativa, un agente no puede depender solo de una ventana temporal de contexto. Necesita consultar información cambiante, respetar permisos y sostener continuidad operativa sin reconstruir el entorno en cada interacción.
"La base de datos en Oracle se volvió el plano de control de los agentes. Los agentes viven dentro del motor de la base de datos".
La afirmación desplaza al LLM desde el centro del control hacia una función instrumental. El modelo sigue siendo relevante para interpretar, razonar o generar lenguaje, pero no debería concentrar por sí solo memoria, estado y reglas de acceso a información interna.
"Los LLM son un instrumento que tiene ese plano de control. Los agentes se ejecutan cerca del dato, donde está el motor, y con eso se elimina latencia, duplicación de datos y parte de la necesidad de vectorizarlos fuera".
El enfoque busca que el agente consulte datos gobernados y preparados dentro del entorno empresarial. En vez de mover información hacia capas adicionales, la operación queda más cerca del repositorio donde ya existen permisos, estructura y control.
RAG, vectorización y menos duplicación
La recuperación aumentada por generación, conocida como RAG, suele requerir fragmentar documentos, indexarlos, vectorizarlos y exponerlos al modelo mediante procesos adicionales. Ese patrón puede ser útil, pero también agrega componentes, movimiento de información y costos de operación.
El vocero sostiene que parte de esa carga se reduce cuando el dato ya está indexado y vectorizado dentro del motor. En ese caso, el agente no necesita trasladar documentos completos ni crear nuevas copias para convertirlos en contexto útil.
"Si esas mil páginas ya están en una tabla indexada y además vectorizada, no tienes que hacer chunking, romper el texto ni vectorizarlo fuera. El motor de base de datos ya entrega esa información vectorizada, con lo que quitas carga computacional de indexación y vectorización al flujo".
El problema también es de gobernanza, porque cada copia adicional puede sumar superficies de riesgo, costos de almacenamiento e inconsistencias. En proyectos de IA empresarial, duplicar datos para cada flujo puede terminar elevando la complejidad que el agente debía reducir.

Memoria persistente y preparación del dato
La memoria del agente debe entenderse como acceso persistente bajo permisos, no como libertad para consultar todo. En entornos corporativos, el sistema solo debería saber lo que la organización autoriza, con jerarquías, políticas internas y límites verificables.
"Si el agente tiene acceso al dato con permisos definidos, puede saber todo lo que se le permite aprender porque trabaja con memoria persistente".
Ese punto refuerza una recomendación práctica para empresas que aún no tienen casos de uso completamente cerrados. Antes de elegir modelos o diseñar automatizaciones complejas, pueden avanzar ordenando y vectorizando información para futuras búsquedas semánticas, análisis documental y flujos con agentes.
"A muchos clientes termino diciéndoles que suban sus datos a una base de datos vectorial y empiecen a vectorizar. El caso de uso puede llegar después, pero si la información ya está vectorizada, están dando varios pasos adelante".
Preparar el dato no equivale a poner IA en producción sin diseño. La ventaja está en reducir fricción cuando la organización necesite consultar información, cruzar documentos o probar un flujo agéntico sin partir desde una base desordenada.

Modelos, producción e infraestructura
La selección de modelos también debería responder a una lógica de experimentación controlada. Según el ejecutivo, comenzar con modelos open source puede reducir costos, comparar respuestas y detectar límites antes de comprometer presupuesto con sistemas comerciales más caros.
"Generalmente recomendamos comenzar con modelos open source para que el costo de experimentación sea muy bajo. Si empiezas de inmediato con un modelo comercial avanzado y con razonamiento extendido, experimentar se vuelve caro".
El paso a producción cambia el estándar técnico. Un agente en sandbox puede trabajar con datos anonimizados, pero un agente conectado a bases de datos, APIs y servicios reales necesita guardrails, permisos, trazabilidad y condiciones operativas claras.
"Cuando un cliente dice que está listo para llevar un agente a producción, hay que definir cuáles serán los guardrails, a qué bases de datos, contextos y sistemas tendrá acceso, cómo será el mecanismo de entrega y con qué frecuencia operará".

La capa física también entra en la discusión cuando los agentes escalan sobre cargas intensivas de IA. El representante de Oracle relaciona ese punto con Acceleron, la arquitectura de la compañía orientada a reducir latencia, mejorar aislamiento y optimizar el acceso a recursos críticos en OCI.
"Cuando hablamos de fierros, el hardware común tiene tres problemas al empezar a hacer IA. Los buses que conectan con las GPU son compartidos, el cómputo que administra los planos de control también es compartido y el acceso a los recursos se administra generalmente por una interfaz de red".














{kind=link}